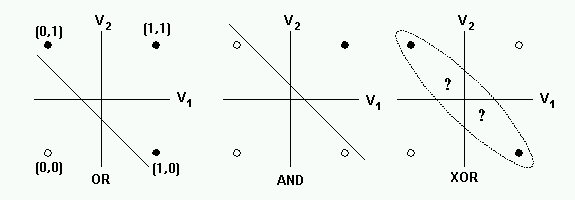심층 신경망(DEEP NEURAL NETWORK)
- 단순 신경망(입력층과 출력층으로 이루어진 모델)은 AND나 OR, NOT 게이트와 같이 선형적인 분류만 가능
- XOR 게이트와 같이 비선형적인 분류를 하기 위해서는 AND와 OR, NOT 게이트를 조합하면 가능했던 것과 같이 신경망에 은닉층으로 추가하면 비선형 분류를 할 수 있다
- 신경망 : 각 뉴런의 발화하는 패턴을 조합하여 데이터를 분류하는 것이기 때문에 뉴런의 개수를 늘려 조합하면 더욱 복잡한 패턴을 인식하고 분류할 수 있음
- 뉴런을 늘리는 방법
- 은닉층에서 뉴런의 개수를 늘리기
- 은닉층의 개수를 늘리기
- 은닉층의 개수를 늘리면 신경망의 층을 더 두텁게 만드는데, 이렇게 두터운 층을 이루는 네트워크를 심층 신경망(Deep Neural Network)라고 하며, 심층 신경망을 학습시키는 기법을 딥러닝(Deep Learning) 또는 심층 학습이라고 한다
MNIST 분류
- MNIST(Modified National Institute of Standards of Technology) 데이터
- TenforFlow
- 5,5000장 : 학습용 데이터
- 1,0000장 : 테스트용 데이터
- 5000장 : 검증용 데이터
- sklearn 또는 keras
- 6,0000장 : 학습용 데이터
- 1,0000장 : 테스트용 데이터
- 7,0000장 이미지 데이터 : 아래 그림과 같이 0에서 9까지의 손글씨 숫자 이미지($28\times 28$ 픽셀)로 각각의 숫자가 레이블(label)임

그림 7.1 MNIST 이미지 데이터
- MNIST 데이터는 sklearn이나 TensorFlow, Keras를 사용해 불러올 수 있다
from sklearn
import datasets
MNIST_sklearn = datasets.fetch_mldata('MNIST original', data_home='.')
X = MNIST_sklearn.data
Y = MNIST_sklearn.target
from tensorflow.examples.tutorials.mnist import input_data
MNIST_TensorFlow = input_data.read_data_sets("../MNIST_data/", one_hot=True)
X_train = MNIST_TensorFlow.train.images
Y_train = MNIST_TensorFlow.train.labels
X_test = MNIST_TensorFlow.test.images
Y_test = MNIST_TensorFlow.test.labels
X_validation = MNIST_TensorFlow.validation.images
Y_validation = MNIST_TensorFlow.validation.labels
from keras.datasets import mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
- MNIST 분류 학습 코드
- 학습 데이터와 테스트 데이터를 합쳐서 1,0000개의 데이터만 사용
- 입력층 차원 : $783(=28\times 28)$
- 은닉층 차원 : $200$개의 뉴런을 사용
import numpy as np
from keras.models
import Sequential
from keras.layers
import Dense, Activation from keras.optimizers
import SGD
from sklearn import datasets
from sklearn.model_selection import train_test_split
MNIST = datasets.fetch_mldata('MNIST original', data_home='.')
n = len(MNIST.data)
N = 10000
indices = np.random.permutation(range(n))[:N]
X = MNIST.data[indices]
Y = MNIST.target[indices]
Y = np.eye(10)[Y.astype(int)]
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.8) # 모델 설정
n_in = len(X[0])
n_hidden = 200
n_out = len(Y[0])
model = Sequential()
model.add(Dense(input_dim=n_in, units=n_hidden))
model.add(Activation('sigmoid'))
model.add(Dense(units=n_out))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1), metrics=['accuracy'])
print(f'\nWhen neurons are , Elapse training time : seconds') # 정확도 측정
start = time()
loss_and_metrics = model.evaluate(x_test, y_test)
print(f'\nLoss : ') print(f'Accuracy : %')
print(f'When neurons are , Elapse test time : seconds')
은닉층 뉴런의 개수에 따른 정확도 비교
- 뉴런 200개일 때
When neurons are 200, Elapse training time : 161.34555006027222 seconds
32/2000 [..............................] - ETA: 0s
2000/2000 [==============================] - 0s 23us/step
Loss : 0.315761 Accuracy : 91.3%
When neurons are 200, Elapse test time : 0.046033620834350586 seconds
- 뉴런 400개일 때
When neurons are 400, Elapse training time : 338.7665045261383 seconds
32/2000 [..............................] - ETA: 0s
1408/2000 [====================>.........] - ETA: 0s
2000/2000 [==============================] - 0s 45us/step
Loss : 0.255655 Accuracy : 92.5%
When neurons are 400, Elapse test time : 0.09006357192993164 seconds
- 뉴런 800개 일 때
When neurons are 800, Elapse training time : 588.1928327083588 seconds
32/2000 [..............................] - ETA: 0s
1248/2000 [=================>............] - ETA: 0s
2000/2000 [==============================] - 0s 49us/step
Loss : 0.282248 Accuracy : 92.6%
When neurons are 800, Elapse test time : 0.09756922721862793 seconds
- 뉴런 1000개일 때
When neurons are 1000, Elapse training time : 737.0927028656006 seconds
32/2000 [..............................] - ETA: 0s
992/2000 [=============>................] - ETA: 0s
1920/2000 [===========================>..] - ETA: 0s
2000/2000 [==============================] - 0s 59us/step
Loss : 1.66926 Accuracy : 84.8%
When neurons are 1000, Elapse test time : 0.11908316612243652 seconds
- 뉴런 2000개일 때
When neurons are 2000, Elapse training time : 1447.6608402729034 seconds
32/2000 [..............................] - ETA: 0s
576/2000 [=======>......................] - ETA: 0s
1056/2000 [==============>...............] - ETA: 0s
1568/2000 [======================>.......] - ETA: 0s
2000/2000 [==============================] - 0s 105us/step
Loss : 1.61429 Accuracy : 87.55%
When neurons are 2000, Elapse test time : 0.21014928817749023 seconds
- 뉴런 4000개일 때
When neurons are 4000, Elapse training time : 2890.275902748108 seconds
32/2000 [..............................] - ETA: 1s
288/2000 [===>..........................] - ETA: 0s
544/2000 [=======>......................] - ETA: 0s
800/2000 [===========>..................] - ETA: 0s
1056/2000 [==============>...............] - ETA: 0s
1312/2000 [==================>...........] - ETA: 0s
1568/2000 [======================>.......] - ETA: 0s
1824/2000 [==========================>...] - ETA: 0s
2000/2000 [==============================] - 0s 217us/step
Loss : 9.80855 Accuracy : 37.95%
When neurons are 4000, Elapse test time : 0.4558277130126953 seconds
- 뉴런 1,0000개일 때
When neurons are 10000, Elapse training time : 6894.483572006226 seconds
32/2000 [..............................] - ETA: 2s
160/2000 [=>............................] - ETA: 0s
288/2000 [===>..........................] - ETA: 0s
416/2000 [=====>........................] - ETA: 0s
544/2000 [=======>......................] - ETA: 0s
672/2000 [=========>....................] - ETA: 0s
832/2000 [===========>..................] - ETA: 0s
960/2000 [=============>................] - ETA: 0s
1088/2000 [===============>..............] - ETA: 0s
1216/2000 [=================>............] - ETA: 0s
1344/2000 [===================>..........] - ETA: 0s
1472/2000 [=====================>........] - ETA: 0s
1600/2000 [=======================>......] - ETA: 0s
1728/2000 [========================>.....] - ETA: 0s
1856/2000 [==========================>...] - ETA: 0s
2000/2000 [==============================] - 1s 414us/step
Loss : 12.5196 Accuracy : 22.1%
When neurons are 10000, Elapse test time : 0.8445994853973389 seconds
- 은닉층 뉴런의 수와 정확도, 학습시간 등의 비교
|
뉴런의 개수 |
학습 시간 |
오차 |
정확도 |
테스트 시간 |
|
$200$개 |
$161.3455$초 |
$0.315761$ |
$91.3\%$ |
$0.0460$초 |
|
$400$개 |
$338.7665$초 |
$0.255655$ |
$92.5\%$ |
$0.0900$초 |
|
$800$개 |
$588.1928$초 |
$0.282248$ |
$92.6\%$ |
$0.0975$초 |
|
$1000$개 |
$737.0927$초 |
$1.66926$ |
$84.8\%$ |
$0.1190$초 |
|
$2000$개 |
$1447.6608$초 |
$1.61429$ |
$87.55\%$ |
$0.2101$초 |
|
$4000$개 |
$2890.2759$초 |
$9.80855$ |
$37.95\%$ |
$0.4558$초 |
|
$1,0000$개 |
$6894.4835$초 |
$12.5196$ |
$22.1\%$ |
$0.8445$초 |
표 7.1 1개의 은닉층에 있는 뉴런의 개수에 따른 성능 비교

그림 7.2 1개의 은닉층에 있는 뉴런의 개수에 따른 성능 비교
-
표 7.1과 그림 7.2를 보면 은닉층의 뉴런의 개수를 늘리더라도 신경망 모델의 예측 정확도가 높아지다가 떨어지는 것을 알 수 있다. 즉, 뉴런의 개수를 단순히 늘린다고 정확도가 높아진다고 볼 수가 없다
- 또한 뉴런의 개수를 늘리면 학습에 걸리는 시간 또한 무시할 수 없을 정도로 길어지는 것을 알 수 있다
- 각 층의 뉴런의 개수를 $n_i, n_h, n_o$로 나타낸다면 각각의 뉴런이 연결되는 가지의 수는 $n_i\times n_h + n_h\times n_o$이기 때문에 모델의 예측 정확도가 동일하다면 은닉층 뉴런의 개수 $n_h$가 작을 수록 좋다
은닉층 뉴런의 개수가 일정할 때 은닉층의 개수에 따른 정확도 비교
- Keras에서 은닉층의 개수를 추가하는 것은 간단하다
from time import time
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD
from sklearn import datasets
from sklearn.model_selection import train_test_split
start = time()
MNIST = datasets.fetch_mldata('MNIST original', data_home='.')
n = len(MNIST.data)
N = 10000
indices = np.random.permutation(range(n))[:N]
X = MNIST.data[indices]
Y = MNIST.target[indices]
Y = np.eye(10)[Y.astype(int)]
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.8) # 모델 설정
n_in = len(X[0])
n_hidden = 200
n_out = len(Y[0])
model = Sequential()
model.add(Dense(input_dim=n_in, units=n_hidden))
model.add(Activation('sigmoid')) # 은닉층 1개 추가
model.add(Dense(units=n_hidden))
model.add(Activation('sigmoid'))
model.add(Dense(units=n_out))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1), metrics=['accuracy']) # 모델 학습
epochs = 1000
batch_size = 100
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size)
print(f'\nWhen hidden layers are 2, Elapse training time : seconds\n') # 정확도 측정
start = time()
loss_and_metrics = model.evaluate(x_test, y_test)
print(f'\nLoss : ')
print(f'Accuracy : %')
print(f'When hidden layers are 2, Elapse test time : seconds')
- 은닉층의 개수가 2개일 때
When hidden layers are 2, Elapse training time : 221.6898009777069 seconds
32/2000 [..............................] - ETA: 0s
2000/2000 [==============================] - 0s 26us/step
Loss : 0.314476 Accuracy : 91.1%
When hidden layers are 2, Elapse test time : 0.05203652381896973 seconds
- 은닉층의 개수가 3개일 때
When hidden layers are 3, Elapse training time : 4.0분 31.61421251296997초
32/2000 [..............................] - ETA: 1s
1408/2000 [====================>.........] - ETA: 0s
2000/2000 [==============================] - 0s 46us/step
Loss : 0.327307 Accuracy : 90.85%
When hidden layers are 3, Elapse test time : 0.0분 0.09306979179382324초
- 은닉층의 개수가 4개일 때
When hidden layers are 4, Elapse training time : 5.0분 7.0608086585998535초
32/2000 [..............................] - ETA: 0s
1920/2000 [===========================>..] - ETA: 0s
2000/2000 [==============================] - 0s 33us/step
Loss : 0.384374 Accuracy : 88.8%
When hidden layers are 4, Elapse test time : 0.0분 0.06604671478271484초 acy
- 은닉층의 개수가 5개일 때
When hidden layers are 5, Elapse training time : 5.0분 32.52758073806763초
32/2000 [..............................] - ETA: 0s
1856/2000 [==========================>...] - ETA: 0s
2000/2000 [==============================] - 0s 35us/step
Loss : 0.43979 Accuracy : 87.55%
When hidden layers are 5, Elapse test time : 0.0분 0.0695500373840332초
- 은닉층의 개수가 6개일 때
When hidden layers are 6, Elapse training time : 6.0분 29.71598792076111초
32/2000 [..............................] - ETA: 1s
1568/2000 [======================>.......] - ETA: 0s
2000/2000 [==============================] - 0s 43us/step
Loss : 0.454472 Accuracy : 86.25%
When hidden layers are 6, Elapse test time : 0.0분 0.0860595703125초
- 은닉층의 개수가 7개일 때
When hidden layers are 7, Elapse training time : 6.0분 53.46243381500244초
32/2000 [..............................] - ETA: 1s
1472/2000 [=====================>........] - ETA: 0s
2000/2000 [==============================] - 0s 44us/step
Loss : 0.90537 Accuracy : 70.2%
When hidden layers are 7, Elapse test time : 0.0분 0.08705806732177734초
- 은닉층의 개수가 8개일 때
When hidden layers are 8, Elapse training time : 7.0분 55.60267639160156초
32/2000 [..............................] - ETA: 1s
1312/2000 [==================>...........] - ETA: 0s
2000/2000 [==============================] - 0s 49us/step
Loss : 2.29931 Accuracy : 12.4%
When hidden layers are 8, Elapse test time : 0.0분 0.09706592559814453초
- 은닉층의 개수가 9개일 때
When hidden layers are 9, Elapse training time : 8.0분 43.596526861190796초
32/2000 [..............................] - ETA: 1s
1152/2000 [================>.............] - ETA: 0s
2000/2000 [==============================] - 0s 55us/step
Loss : 2.30193 Accuracy : 9.95%
When hidden layers are 9, Elapse test time : 0.0분 0.11157894134521484초
- 은닉층의 개수가 10개일 때
When hidden layers are 10, Elapse training time : 9.0분 0.5422961711883545초
32/2000 [..............................] - ETA: 1s
1216/2000 [=================>............] - ETA: 0s
2000/2000 [==============================] - 0s 50us/step
Loss : 2.30177 Accuracy : 10.05%
When hidden layers are 10, Elapse test time : 0.0분 0.10107207298278809초
- 은닉층의 개수가 50개일 때
When hidden layers are 50, Elapse training time : 37.0분 29.942996501922607초
32/2000 [..............................] - ETA: 6s
288/2000 [===>..........................] - ETA: 0s
544/2000 [=======>......................] - ETA: 0s
832/2000 [===========>..................] - ETA: 0s
1120/2000 [===============>..............] - ETA: 0s
1408/2000 [====================>.........] - ETA: 0s
1696/2000 [========================>.....] - ETA: 0s
1984/2000 [============================>.] - ETA: 0s
2000/2000 [==============================] - 0s 245us/step
Loss : 2.30093 Accuracy : 12.5%
When hidden layers are 50, Elapse test time : 0.0분 0.5073604583740234초|
은닉층의 개수 |
학습 시간 |
오차 |
정확도 |
테스트 시간 |
|
$1$개 |
$2$분 $41.33$초 |
$0.3157$ |
$91.3\%$ |
$0.046$초 |
|
$2$개 |
$3$분 $41.69$초 |
$0.3144$ |
$91.1\%$ |
$0.052$초 |
|
$3$개 |
$4$분 $31.61$초 |
$0.3273$ |
$90.85\%$ |
$0.093$초 |
|
$4$개 |
$5$분 $7.06$초 |
$0.3844$ |
$88.8\%$ |
$0.066$초 |
|
$5$개 |
$5$분 $32.52$초 |
$0.4398$ |
$87.55\%$ |
$0.069$초 |
|
$6$개 |
$6$분 $29.71$초 |
$0.4545$ |
$86.25\%$ |
$0.086$초 |
|
$7$개 |
$6$분 $53.46$초 |
$0.9054$ |
$70.2\%$ |
$0.087$초 |
|
$8$개 |
$7$분 $55.60$초 |
$2.2993$ |
$12.4\%$ |
$0.097$초 |
|
$9$개 |
$8$분 $43.59$초 |
$2.3019$ |
$9.95\%$ |
$0.112$초 |
|
$10$개 |
$9$분 $0.54$초 |
$2.3017$ |
$10.05\%$ |
$0.101$초 |
|
$50$개 |
$37$분 $29.94$초 |
$2.3009$ |
$12.5\%$ |
$0.507$초 |
표 7.2 200개의 뉴런을 가진 은닉층의 개수에 따른 성능 비교
- 표 7.2의 결과는 표 7.1처럼 뉴런의 개수랑 은닉층의 개수를 무작정 늘린다고 예측 결과의 정확도가 높아지지는 않고 오히려 더 떨어지는 결과를 보여준다. 특히 은닉층이 8개인 경우에는 거의 학습이 되지 않았다는 것을 알 수 있다.
PyTorch 코드
- 학습을 위한 코드
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import random
from time import time
USE_CUDA = torch.cuda.is_available() # GPU를 사용가능하면 True, 아니라면 False를 리턴
device = torch.device("cuda" if USE_CUDA else "cpu") # GPU 사용 가능하면 사용하고 아니면 CPU 사용
print("다음 기기로 학습합니다:", device)
# for reproducibility
random.seed(777)
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# dataset loader
batch_size = 100
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size, # 배치 크기는 100
shuffle=True,
drop_last=True)
# MNIST 데이터 이미지의 크기: 28 * 28 = 784
linear = torch.nn.Linear(784, 10, bias=True).to(device)
# 매개변수
training_epochs = 15
batch_size = 100
# cost/loss 함수와 optimizer 정의
criterion = torch.nn.CrossEntropyLoss().to(device) # 내부적으로 Softmax로 계산됨
optimizer = torch.optim.SGD(linear.parameters(), lr=0.1)
start = time()
for epoch in range(training_epochs): # 앞서 training_epochs의 값은 15로 지정함.
avg_cost = 0
total_batch = len(data_loader)
for X, Y in data_loader:
# 배치 크기가 100이므로 아래의 연산에서 X는 (100, 784)의 텐서가 된다.
X = X.view(-1, 28 * 28).to(device)
# 레이블은 원-핫 인코딩이 된 상태가 아니라 0 ~ 9의 정수.
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print(f'Epoch: {epoch + 1:>04d}/{training_epochs:2d}, cost = {avg_cost:>12.9f}')
print(f'Learning finished, Elapse test time : {time() - start:10.4f}seconds')다음 기기로 학습합니다: cuda
Epoch: 0001/15, cost = 0.534912467
Epoch: 0002/15, cost = 0.359308600
Epoch: 0003/15, cost = 0.331088215
Epoch: 0004/15, cost = 0.316574216
Epoch: 0005/15, cost = 0.307130307
Epoch: 0006/15, cost = 0.300207883
Epoch: 0007/15, cost = 0.294897258
Epoch: 0008/15, cost = 0.290830433
Epoch: 0009/15, cost = 0.287419587
Epoch: 0010/15, cost = 0.284589082
Epoch: 0011/15, cost = 0.281816214
Epoch: 0012/15, cost = 0.279919684
Epoch: 0013/15, cost = 0.277836859
Epoch: 0014/15, cost = 0.276022315
Epoch: 0015/15, cost = 0.274443209
Learning finished, Elapse test time : 69.0733seconds
- 모델 테스트
# 테스트 데이터를 사용하여 모델을 테스트한다.
with torch.no_grad(): # torch.no_grad()를 하면 gradient 계산을 수행하지 않는다.
start = time()
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = linear(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print(f'Evaluating finished, Elapse test time : {time() - start:10.4f}seconds')
print(f'Accuracy: {accuracy.item()*100:.4}%' )
# MNIST 테스트 데이터에서 무작위로 하나를 뽑아서 예측을 해본다
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = linear(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
plt.imshow(mnist_test.test_data[r:r + 1].view(28, 28), cmap='Greys', interpolation='nearest')
plt.show()Evaluating finished, Elapse test time : 0.0279seconds
Accuracy: 88.68%
Label: 5
Prediction: 3
학습시킬 때 발생하는 문제점
- 신경망 모델에서 뉴런의 개수나 은닉층의 개수를 늘리기만 한다고 좋은 결과가 나오지 않은 이유는 크게 2가지로 볼 수 있음
- 경사 소실 문제(vanishing gradient problem)
- 오버피팅 문제(overfitting problem)
경사 소실 문제
- 신경망 모델을 학습시킬 때, 우리는 오차함수에 대한 최적해를 구하기 위해 매개변수의 경사를 구해야하는데 이 과정에서 경사가 없어져버리는($0$이 돼 버리는) 문제를 경사 소실 문제(vanishing gradient problem)라고 한다.
- 경사가 소실되면 오차 역전파법을 제대로 실행할 수가 없는데, 표 7.2와 같이 은닉층의 개수가 늘어날수록 경사 소실 문제가 현저하게 나타난다.
- 그림 7.3과 같이 은닉층이 2개인 신경망 모델을 생각해보면 각 층에서 나오는 뉴런의 출력은 각각 식 $(7.1)$, 식 $(7.2)$, 식 $(7.3)$과 같이 쓸 수 있다.
- $\mathbb{x}$ : 입력층의 값
- $\mathbb{h}_{(1)}, \mathbb{h}_{(2)}$ : 은닉층 2개
- $\mathbb{y}$ : 출력층의 값
- $\mathbf{W}, \mathbf{V}, \mathbf{U}$ : 각 층간의 웨이트 행렬
- $\mathbb{b}, \mathbb{c}, \mathbb{d}$ : 각 층의 바이어스 벡터
- $\sigma(\cdot)$ : 활성화를 시그모이드 함수

그림 7.2 은닉층이 2개인 4층 신경망 모델
$$\begin{align} \mathbb{h}_{(1)} &= \sigma(\mathbf{W}\mathbb{x} + \mathbb{b}) \tag{7.1}\\ \mathbb{h}_{(2)} &= \sigma(\mathbf{V}\mathbb{h}_{(1)} + \mathbb{c}) \tag{7.2}\\ \mathbb{y} &= \textrm{softmax}(\mathbf{U}\mathbb{h}_{(2)} + \mathbb{d}) \tag{7.3} \end{align}$$
- 다층 퍼셉트론을 모델화했을 때처럼 식 $(7.1)$과 식 $(7.2)$, 식 $(7.3)$을 다음과 같이 놓으면 웨이트 행렬 $\mathbf{W}=(\mathbb{w}_1, \mathbb{w}_2,\ldots, \mathbb{w}_J)$에 대한 경사는 식 $(7.7)$과 같이 나타낼 수 있다.
$$\begin{align} \mathbb{p} &= \mathbf{W}\mathbb{x} + \mathbb{b} \tag{7.4}\\ \mathbb{q} &= \mathbf{V}\mathbb{h}_{(1)} + \mathbb{c} = \mathbf{V}\big(\sigma(\mathbf{W}\mathbb{x} + \mathbb{c})\big) +\mathbb{c} = \mathbf{V}\cdot\sigma(\mathbb{p})+\mathbb{c}\tag{7.5}\\ \mathbb{r} &= \mathbf{U}\mathbb{h}_{(2)} + \mathbb{d} = \mathbf{U}\big(\sigma(\mathbf{V}\mathbb{h}_{(1)} + \mathbb{c})\big) +\mathbb{d} = \mathbf{U}\cdot\sigma(\mathbb{q}) +\mathbb{d}\tag{7.6} \end{align}$$
$$\begin{align} \frac{\partial E_n}{\partial \mathbb{w}_j} &= \frac{\partial E_n}{\partial \mathbb{p}_j} \frac{\partial \mathbb{p}_j}{\partial \mathbb{w}_j} \\&=\frac{\partial E_n}{\partial \mathbb{p}_j}\frac{\partial}{\partial \mathbb{w}_j}\Big(\not{\mathbf{W}}\mathbb{x}+\not{\mathbb{b}}\Big) \\ &=\frac{\partial E_n}{\partial \mathbb{p}_j}\mathbb{x} \tag{7.7}\end{align}$$
- 식 $(7.7)$에서 우리는 $\frac{\partial E_n}{\partial \mathbb{p}_j}$만 계산하면 되는데, 신경망 모델이 $3$층인 경우 편미분의 연쇄법칙(chain rule)을 적용하면 식 $(7.8)$과 식 $(7.9)$, 식 $(7.10)$과 같이 계산할 수 있다.
$$\begin{align} \frac{\partial E_n}{\partial \mathbb{p}_j} &= \sum_{k=1}^K \frac{\partial E_n}{\partial \mathbb{q}_k}\frac{\partial \mathbb{q}_k}{\partial \mathbb{p}_j}\tag{7.8}\\&= \sum_{k = 1}^K \frac{\partial E_n}{\partial \mathbb{q}_k}\frac{\partial}{\partial \mathbb{p}_j} \Big(\mathbf{V}\sigma(\mathbb{p})+\not{\mathbb{c}}\Big)\tag{7.9}\\&= \sum_{k=1}^K\frac{\partial E_n}{\partial \mathbb{q}_k}\Big(\mathbb{v}_{k_j}\sigma'(\mathbb{p}_j)\Big)\tag{7.10}\end{align}$$
- 신경망 모델이 $4$층인 경우에는 추가로 $\frac{\partial E_n}{\partial \mathbb{q}_k}$도 구해야 하기 때문에 편미분의 연쇄법칙을 한번 더 사용해서 식 $(7.11)$과 식 $(7.12)$, 식 $(7.13)$을 만들 수 있다.
$$\begin{align} \frac{\partial E_n}{\partial \mathbb{q}_k} &= \sum_{\ell=1}^L \frac{\partial E_n}{\partial \mathbb{r}_\ell}\frac{\partial \mathbb{r}_\ell}{\partial \mathbb{q}_k}\tag{7.11}\\&= \sum_{\ell = 1}^L \frac{\partial E_n}{\partial \mathbb{r}_\ell}\frac{\partial}{\partial \mathbb{q}_k} \Big(\mathbf{U}\sigma(\mathbb{q})+\not{\mathbb{d}}\Big)\tag{7.12}\\&= \sum_{\ell=1}^L\frac{\partial E_n}{\partial \mathbb{r}_\ell}\Big(\mathbb{u}_{\ell_k}\sigma'(\mathbb{q}_k)\Big)\tag{7.13}\end{align}$$
- $\frac{\partial E_n}{\partial \mathbb{r}_\ell}$은 출력층 부분이기 때문에 식 $(7.14)$와 같이 나타낼 수 있다.
$$ \frac{\partial E_n}{\partial \mathbb{r}_\ell} = -\Big(\mathbb{y}_\ell - H_\ell(\mathbb{x}_\ell)\Big)\tag{7.14}$$
- 식 $(7.14)$는 신경망 네트워크의 오차에 해당하기 때문에 오차를 다음과 같이 정의하면
$$\begin{align} \delta_j &= \frac{\partial E_n}{\partial \mathbb{p}_j}\tag{7.15} \\ \delta_k &= \frac{\partial E_n}{\partial \mathbb{q}_k}\tag{7.16}\\\delta_\ell &= \frac{\partial E_n}{\partial \mathbb{r}_\ell}\tag{7.17}\end{align}$$
- 식 $(7.15)$는 식 $(7.10)$과 식 $(7.13)$에 의해 다음과 같이 정리하면 4층 신경망 네트워크에서 사용할 수 있는 오차역전파법의 식 $(7.22)$얻을 수 있다.
$$\begin{align}\delta_j &= \frac{\partial E_n}{\partial \mathbb{p}_j} \tag{7.18}\\&= \sum_{k=1}^K \frac{\partial E_n}{\partial \mathbb{q}_k}\Big(\mathbb{v}_{k_j}\sigma'(\mathbb{p}_j)\Big)\quad\big(\because\,\, (7.10)\big)\tag{7.19}\\&= \sum_{k=1}^K\Bigg(\sum_{\ell=1}^L\frac{\partial E_n}{\partial \mathbb{r}_\ell} \Big(\mathbb{u}_{\ell_k} \sigma'(\mathbb{q}_k)\Big)\Bigg)\Big(\mathbb{v}_{k_j}\sigma'(\mathbb{p}_j)\Big)\quad\big(\because\,\, (7.13)\big)\tag{7.20}\\&= \sum_{k=1}^K\sum_{\ell=1}^L\delta_\ell \Big(\mathbb{u}_{\ell_k}\sigma'(\mathbb{q}_k)\Big)\Big(\mathbb{v}_{k_j}\sigma'(\mathbb{p}_{j})\Big)\quad\big(\because\,\, (7.17)\big)\tag{7.21}\\&= \sum_{k=1}^K\sum_{\ell=1}^L\Big(\mathbb{u}_{\ell_k}\mathbb{v}_{k_j}\Big)\Big(\sigma'(\mathbb{q}_k)\sigma'(\mathbb{p}_j)\Big)\delta_\ell \tag{7.22}\end{align}$$
- 이론적으로는 은닉층의 개수가 늘어도 편미분의 연쇄법칙을 반복해서 적용하면 정형화된 식을 통해 각 매개변수의 경사를 구할 수 있다.
- 그러나 식 $(7.22)$를 코드로 구현할 때에는 문제가 발생할 수 있는 부분이 있는데, 바로 뉴런의 활성화를 위한 시그모이드 함수가 사용되는 부분이다. 식 $(7.22)$ 오차역전파식에는 '시그모이드 함수를 미분한 것들의 곱' 부분이 있는데 우리는 시그모이드 함수를 미분하면 식 $(7.23)$이 되는 것을 알고 있으며, 이를 그래프로 나타내면 그림 $(7.3)$과 같다.
$$\sigma'(x) = \sigma(x)\big(1-\sigma(x)\big) \tag{7.23}$$

그림 7.3 시그모이드 함수 $\sigma(x)$와 시그모이드를 미분한 도함수 $\sigma'(x)$의 그래프
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.linspace(-10, 10, 1000)
y = np.array([sigmoid(x) for x in x])
z = np.array([sigmoid(x)*(1-sigmoid(x)) for x in x])
plt.plot(x, y, label='$\sigma(x)$')
plt.plot(x, z, label='$\sigma\'(x)$')
plt.grid(linestyle='--', color='lavender')
plt.legend()
plt.show()
- 그림 $(7.3)$에서 알 수 있듯이 시그모이드 함수의 도함수 $\sigma'(x)$는 $x=0$일 때 최댓값 $\sigma'(x)=0.25$가 된다. 은닉층이 2개 있는 4층 신경망 모델에서 오류역전파 식 (7.22)의 값을 계산할 때에는 $0.25^2$이 곱해지는 것을 알 수 있으며, 은닉층이 $N$개인 경우에 오차를 계산할 때 $\alpha_N\leqq 0.25^N < 1$ 범위에 있는 $\alpha_N$이 곱해진다는 것을 알 수 있으며 $N$이 커지면 $\alpha_N$ 또한 $0$에 수렴하는 것을 알 수 있다.
$$\lim_{N\rightarrow\infty}{\alpha_N} = \lim_{N\rightarrow\infty} \Bigg(\frac{1}{4}\Bigg)^N=0 \tag{7.24}$$
- 은닉층이 많아지면 오류역전파식을 통해 오차를 계산할 때 식 $(7.24)$로 인하여 오차항의 값이 $0$에 가까워지는 현상을 경사 소실 문제(vanishing gradient problem)이라고 하며, 이를 해결하기 위해서는 미분을 하더라도 값이 작아지지 않는 활성 함수를 사용해야만 한다.
- 또한 경사 소실 문제는 은닉층이 많지 않더라도 발생할 수 있는데, 각 층의 차원(뉴런의 수)이 높아지는 경우에 시그모이드 함수를 통해 활성화되는 $\mathbf{W}\mathbb{x}+\mathbb{b}$의 값이 커질 수 있어 경사가 소실될 수 있다.
- $\mathbf{W}=(\mathbb{w}_1, \mathbb{w}_2, \ldots, \mathbb{w}_n)$이라고 하면 그림 $(7.3)$에서 알 수 있듯이 시그모이드 함수의 입력값이 커지기 때문에 식 $(7.25)$가 성립한다. 따라서 식 $(7.26)$으로 인해 경사가 소실될 수 있다.
$$\lim_{n\rightarrow\infty} \sigma\big(\mathbf{W}\mathbb{x}+\mathbb{b}\big) = 1 \tag{7.25}$$
$$\begin{align}\lim_{n\rightarrow\infty} \sigma'\big(\mathbf{W}\mathbb{x}+\mathbb{b}\big) &= \lim_{n\rightarrow\infty}\sigma\big(\mathbf{W}\mathbb{x}+\mathbb{b}\big)(1-\sigma(\mathbf{W}\mathbb{x}+\mathbb{b})) \\&= 1\cdot(1-1)\\&=0 \tag{7.26}\end{align}$$
오버피팅 문제
- 오버피팅(overfitting)은 예측 모델이 학습 데이터에만 최적화되어 테스트 데이터를 제대로 예측하지 못하는 상태를 말하며 과학습 또는 과잉적합이라고도 한다.
- 오버피팅의 예를 설명하기 위해 그림 $7.4$와 같이 실제 분포는 $f(x)=\cos(\fracx)$일 때, 이 분포를 따르는 30개의 데이터가 있다고 해보자.

그림 7.4 $f(x)=\cos(\frac{3\pi}{2}x)$ 분포를 따르는 30개의 샘플 데이터
import numpy as np
import matplotlib.pyplot as plt
M = 2
e = np.random.randn(30) * 0.1
x = np.linspace(0, 1, 100)
y = np.cos(3*np.pi / 2 * x)
x1 = np.sort(np.random.choice(x, 30, replace=False))
y1 = np.cos(3*np.pi / 2 * x1) + e
plt.scatter(x1, y1, facecolor='red', label='sample data')
plt.plot(x, y, color='lightgrey', label='$\cos(/x)$')
plt.grid(linestyle='--', color='lavender')
plt.legend()
plt.show()
- 30개의 샘플 데이터를 보고 분포 $\cos(\frac{3\pi}{2}x)$ 모델을 찾을 수 있으면 좋겠지만 실제로는 학습 데이터만 보고 모델을 찾는 것이 쉽지 않다.
- 데이터 분류 및 예측을 위한 신경망 모델은 학습 데이터를 통해 가능한 한 실제 분포 함수와 가까운 함수로 근사해서 예측 정확도를 높여야 하기 때문에 근사치를 구하기 위해 사용되는 함수를 어떻게 설정하는지가 중요하다.
- 식 $(7.27)$과 같은 다항식 함수로 회귀분석 하는 방법을 생각해보자.
$$\begin{align} \hat{f}(x) &=a_0+a_1x + a_2x^2+ \cdots + a_nx^n\\&= \sum_{i=0}^na_ix^i\tag{7.29}\end{align}$$
- $n=1$일 경우에 $\hat(x)=a_0+a_1x$이기 때문에 직선으로 표현되며, $n=2$인 경우에는 2차 함수 곡선으로 표현할 수 있다. 따라서 $n$을 크게하면 더 복잡한 곡선을 표현할 수 있는데, 실제로는 $n$을 크게 하더라도 정확하게 표현하는 것이 쉽지 않다.
- 그림 $7.5$는 $n=1, 4, 33$일 때 30개의 샘플 데이터를 사용해 회귀 분석한 것으로 $n=1$일 때에는 직선으로 표현할 수 밖에 없어 샘플 데이터를 제대로 표현할 수가 없으며, $n=33$일 때에는 더욱 복잡한 함수를 표현할 수 있지만 샘플 데이터만 표현하는 것에 맞춰 회귀되었기 때문에 결과적으로는 실제 분포인 $\cos(\frac{3\pi}{2}x)$와는 다소 거리가 있다.

그림 7.5 1차 함수 회귀(왼쪽), 4차 함수 회귀(중간), 33차 함수로 회귀(오른쪽)
- 이는 샘플 데이터의 개수가 한정돼 있기 때문에 주어진 데이터만 잘 표현할 수 있는 분포 함수를 찾았다고 하더라도 이 분포 함수가 새롭게 발생되는 미지의 데이터도 잘 표현할 수 있도는 장담을 할 수가 없다. $n=33$일 때처럼 샘플 데이터만을 과잉으로 회귀하는 상태를 오버피팅이라고 한다.
- 은닉층이나 은닉층의 뉴런 개수를 늘려도 신경망 모델을 구성하는 전체 뉴런의 개수가 늘어나기 때문에 더욱 복잡한 패턴을 표현할 수 있지만 학습 데이터만을 복잡한 방법으로 표현한다면 데이터의 실제 분포와는 다른 패턴 분류의 형태가 될 가능성이 높아진다.
- 신경망 모델을 학습시킬 때는 오차 함수 $E$값이 최소가 되도록 매개변수 값을 변경했지만 단순히 $E$를 최소화하면 오버피팅될 가능성이 있기 때문에 무조건 최소화시키기만 하면 좋은 것은 아니다.
- 학습 데이터는 예측이 잘 되지만 테스트 데이터는 예측이 잘 안된다면 오버피팅을 의심해봐야만 한다.
출처 : 정석으로 배우는 딥러닝
'신경망(Neural Network) 스터디' 카테고리의 다른 글
| 9. 오버피팅 문제 해결 (0) | 2018.01.19 |
|---|---|
| 8. 경사 소실 문제 해결하기 (0) | 2018.01.18 |
| 6. 다층 퍼셉트론 모델링 (0) | 2017.12.28 |
| 5. 다중 클래스 로지스틱 회귀 (0) | 2017.12.27 |
| 4. 로지스틱 회귀 (0) | 2017.12.23 |