$A$를 $n\times n$ 크기의 정방행렬(square matrx)라고 하자. 벡터 $\mathbf{x}(\neq \mathbf{0}) \in \mathbf{R}^n$에 대해 다음 식 $(1)$을 만족하는 스칼라 $\lambda \in \mathbf{R}$가 존재할 때 벡터 $\mathbf{x}$를 행렬 $A$의 고유벡터(eigenvector) 또는 특성벡터(characteristic vector)라고 한다.
$$A\mathbf{x}=\lambda \mathbf{x}\tag{1}$$
스칼라 $\lambda$는 행렬 $A$의 고유값(eigenvalue) 또는 특성값(characteristic value)라고 하며, 벡터 $\mathbf{x}$가 $\lambda$에 속한다(belong to)고 한다.
기하학적 의미
행렬 $A$의 고유벡터는 $n$차원 공간 $\mathbf{R}^n$에서 $\mathbf{0}$이 아닌 벡터 $\mathbf{x}$로 $A\mathbf{x}$와 평행(parallel)$하다.
대수적 의미
고유벡터 $\mathbf{x}$는 동차연립1차방정식(homogeneous system of linear equation)(식 $(2)$)의 자명하지 않은 해(nontrivial solution)이다.
$$(\lambda I - A)\mathbf{x}=\mathbf{0}\tag{2}$$
즉, 고유벡터 $\mathbf{x}$는 영공간(null space) $\mathcal{N}(\lambda I - A)$에서 $\mathbf{0}$이 아닌 벡터이다.
위의 식 $(2)$에서 고유값 $\lambda$와 고유벡터 $\mathbf{x}$의 값을 알아야 한다.
고유값 $\lambda$ 찾기
방정식 $(\lambda I - A)\mathbf{x}=\mathbf{0}$이 자명하지 않은 해 $\mathbf{x}$를 갖는다는 것과$\lambda$가 방정식 $(3)$을 만족한다는 것과 필요충분조건이라는 사실을 통해 고유값 $\lambda$를 찾아야 한다.
$$\textrm{det}(\lambda I - A) = \mathbf{0}\tag{3}$$
방정식 $(3)$의 좌변은 $\lambda$에 대한 $n$차 다항식으로 $A$의 특성다항식(characteristic polynomial)이라고 한다. 따라서 고유값은 방정식 $(3)$의 근(root)이 된다.
$A$의 고유벡터를 찾기 위해서는 먼저 방정식 $(3)$의 근 또는 $A$의 고유값을 구한 다음, 각각의 고유값 $\lambda$에 대해 동차연립 $(2)$를 풀어야 한다.
어떤 사건이 일어날 것으로 예상될 때, 그 사건이 일어나도 이상하지 않은지 또는 거의 일어나지 않는데 어떤 특별한 이유(배경 요인)로 인해 일어나는 사건인지 알아보고 싶은 경우에 사용하는 증명 과정이다.
귀무가설
통계적 검정을 하기 위한 전제 조건으로 먼저 가설을 설정하는 데 이 가설을 귀무가설(null hypothesis)라고 한다. 설문조사나 연구에서 증명하고자 하는 것, 예를 들어 'A와 B가 차이가 있다'는 것을 증명하기 위해 'A와 B가 차이가 없다'는 가정이 귀무가설이다. 귀무가설과 정반대되는 가설을 '대립가설'이라고 한다.
일반적으로 통계적 검증은 수학 증명 과정에서 가정을 했는데, 마지막에 가정과 모순되는 결론에 도달하면 가정이 잘못되었다는 것을 증명하는 귀류법(歸謬法, proof by contradiction)을 사용한다. 즉, 'A와 B가 차이가 없다'고 가정을 했지만, 증명을 통해 'A와 B가 차이가 있다'라는 결과를 얻어 가정에 위배되는 모순이 발생했으므로 , 'A와 B가 차이가 없다'는 가정이 잘 못 되었다. 따라서 , 'A와 B는 차이가 있어야 한다'고 결론을 내리는 과정이다. 요약하면 귀무가설을 기반으로 '일어날 가능성이 없는 사건이 발생했다'는 모순을 입증하는 과정이 바로 '통계적 검증'이다.
귀무가설을 기반으로 실제로 일어날 사건이 '발생할 확률'을 계산하는데 다양한 통계학 이론이 사용된다. 어떤 확률분포를 따르는 검정 통계량을 구하고, 이 통계량의 값이 사전에 정의한 유의수준보다 높다면(즉, 신뢰구간 안에 있다면) 일어날 만해서 일어난 사건이므로 처음 설정한 가설(귀무가설)이 옳다고 할 수 있다. 이를 '귀무가설이 채택되었다'고 한다. 이 경우, 우리는 실제로 대립가설이 옳지만 틀린 귀무가설을 채택하는 오류를 범할 수 있다. 이런 오류를 II종 오류(Type II-error) 또는 False Negative Rate(FNR)이라고 한다.
통계량의 확률이 사전에 정의한 유의 준보다 낮다면(즉, 신뢰구간 밖에 있다면) 일어날 가능성이 없는 사건이 일어났다는 것을 의미한다. 즉, 처음 설정한 가설(귀무가설)이 틀렸으므로 '대립가설을 채택한다'고 한다. 이 경우, 우리는 실제로 귀무가설이 옳지만 틀린 대립가설을 채택하는 오류를 범할 수 있다. 이런 오류를 I종 오류(Type I-error) 또는 False Positive Rate(FPR)이라고 한다.
예를 들어, 평균값을 \(\bar{x}\), 표본표준편차를 \(s\), 모평균을 \(\mu\), 표본 수를 \(n\)이라고 했을 경우, 표본집단의 분산, 즉 표본분산을 사용해 표준화한 통계량 \(t\)는 자유도가 \(n-1\)인 \(t\)-분포를 따른다.
$$ t = \frac{|\bar{x}-\mu|}{\frac{s}{\sqrt{n}}} $$
따라서 통계량 \(t\)가 유의수준 \(\alpha\)에 대하여 \(t\)-분포의 신뢰구간 \(t_{(-\frac{\alpha}{2},n-1)}\)과 \(t_{(\frac{\alpha}{2},n-1)}\) 사이에 있으면 귀무가설을 채택하고, 신뢰구간 밖에 있으면 귀무가설을 기각하고 대립가설을 채택하면 된다.
다음의 경우 귀무가설 \(H_0\) 채택
$$t_{(-\frac{\alpha}{2},n-1)}\leqq t \leqq t_{(\frac{\alpha}{2},n-1)}$$
통계적 검정에서 '판단의 기준'인 동시에 '판단을 실수할 가능성' \(\alpha\)를 의미한다. 통상적으로 \(5%(=0.05)\)를 사용하지만, 엄격한 기준이 필요한 경우에는 \(1%\)나 \(0.1%\)를 사용하기도 한다.
신뢰구간
구간 추정(interval estimation)은 구간의 상계와 하계를 정해서 통계량이 존재하는 범위, 즉 구간을 알아내는 방법이다. 이 때 하계를 좌측 신뢰 구간 한계, 상계를 우측 신뢰구간 한계라고 한다. 하계와 상계를 구하기 위한 존재 확률 \(1-\alpha\)을 신뢰 계수(confidence coefficient) 라고 한다.
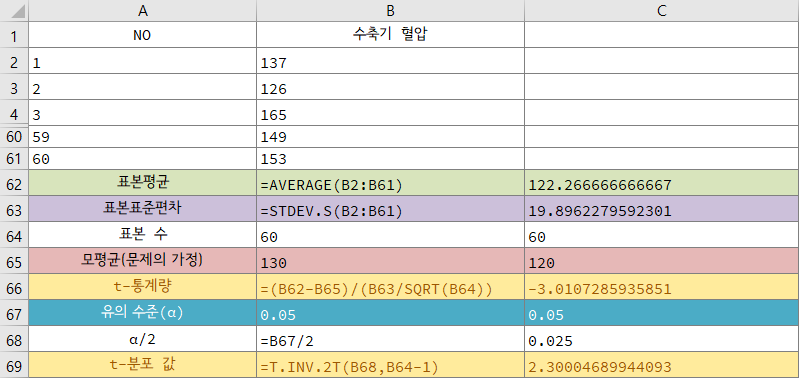
환자 60명의 수축기 혈압 평균값이 \(122.2666\textrm{mmHg}\)이고, 표본표준편차가 \(19.8962\textrm{mmHg}\)일 때, 모평균의 값이 \(120\textrm{mmHg}\)일까? 또는 \(130\textrm{mmHg}\)일 가능성도 있을까? 유의수준 \(5%\)로 검정을 해보자.
먼저 귀무가설과 대립가설을 설정한다.
모평균 \(\mu=120\textrm{mmHg}\)인 경우 다음과 같다.
귀무가설 \(H_0\): \(\mu =120\textrm{mmHg}\)이다.
대립가설 \(H_1\): \(\mu \neq 120\textrm{mmHg}\)이다.
표본평균값이 \(122.2666\textrm{mmHg}\)이고, 표본표준편차가 \(19.8962\textrm{mmHg}\), 모평균이 가정에 따라 \(120\textrm{mmHg}\), 표본 수가 \(60\)일 때, 통계량 \(t\)의 값은 다음과 같다.
$$ \begin{aligned} t &= \frac{|\bar{x}-\mu|}{\frac{s}{\sqrt{n}}}\\ &=\frac{|122.2666-120|}{\frac{19.8962}{\sqrt{60}}}\\ &\approx 0.8825 \end{aligned} $$
표본 수가 \(60\)이고, 유의수준 \(\alpha\)가 \(5%\)인 \(t\)-분포 \(t_{(\frac{\alpha}{2},n-1)}\)는 다음과 같다.
따라서, \(t(\approx 0.8825)\ll t_{(\frac{\alpha}{2},n-1)}(\approx 2.3005)\)이므로 '모평균이 \(120\textrm{mmHg}\)이다'라는귀무가설을 채택할 수 있다. 이 때 귀무가설이 틀리고, 대립가설이 옳을 오류는 \(5\%\)이다.
두 번째 경우를 살펴보자.
먼저 귀무가설과 대립가설을 설정한다.
모평균 \(\mu=130\textrm{mmHg}\)인 경우 다음과 같다.
귀무가설 \(H_0\): \(\mu =130\textrm{mmHg}\)이다.
대립가설 \(H_1\): \(\mu \neq 130\textrm{mmHg}\)이다.
모평균이 \(130\textrm{mmHg}\)이고, 표본 수가 \(60\)일 때, 통계량 \(t\)의 값은 다음과 같다.
$$ \begin{aligned} t &= \frac{|\bar{x}-\mu|}{\frac{s}{\sqrt{n}}}\\ &=\frac{|122.2666-130|}{\frac{19.8962}{\sqrt{60}}}\\ &\approx 3.0107 \end{aligned} $$
따라서, \(t(\approx 3.0107)> t_{(\frac{\alpha}{2},n-1)}(\approx 2.3005)\)이므로, '모평균이 \(130\textrm{mmHg}\)이다'라는 귀무가설을 기각하고, '모평균이 \(130\textrm{mmHg}\)아니다'라는 대립가설을 채택할 수 있다. 이 때 귀무가설이 옳지만 대립가설을 선택하는 오류는 \(5\%\)이다.
즉, 이 검정의 결론은 모평균은 \(120\textrm{mmHg}\)일 수는 있지만 \(130\textrm{mmHg}\)은 될 수 없다는 것이다.
Q: 모집단의 참값을 어떻게 해야 구할 수 있을까? A: 모집단의 참값은 알 수가 없지만 어떤 가능성 하에 참값이 존재하는 구간을 추정할 수 있다.
구간추정(interval estimation): 모집단의 참값이 들어있는 신뢰구간(confidence interval)의 폭이 정해지면 구할 수 있다.
이 폭은 참값이 들어있을 가능성(신뢰성 계수 또는 신뢰도(coefficient of reliability))으로 정해진다
가능성: ↑ 폭: ↑
Q: 추정한 결과가 올바른지 알 수 있을까? A: 통계적 검정(statistical test)를 통해 판단한다
측정값과 오차
모집단의 원소에 대한 측정값 \($x_i\)는 다음과 같은 조건에 영향을 받는다.
동일한 모집단에 포함되어 있다.
모집단의 원소 각각은 어떤 특성 \(f_i\)을 갖는다.
측정 시 오차(\(\varepsilon_i\))가 발생한다.
따라서 모집단의 평균이 \(\mu\)일 때 표본 \(i\)의 측정값 \(x_i\)는 다음과 같다. $$ x_i = \mu + f_i + \varepsilon_i $$ 위 식에서 \(\sum_if_i=0\)인데 표본의 값이 평균보다 큰 것도 있고, 작은 것도 있을텐데 전체적으로 보면 이런 차이는 미미하다는 의미이다. 또한 \(\sum_i\varepsilon_i=0\)인데 측정을 반복하다 보면 측정오차는 점점 줄어든다는 의미이다.
다시 말하면, 모든 원소의 특성과 오차의 합계는 모두 \(0\)이 되므로 표본이 많을 수록 그 결과는 모집단에 가까워질 수 밖에 없다. 그러나 실제로는 모든 원소에 대해 측정하는 것은 불가능한 경우가 많으므로 모집단 평균의 참값 \(\mu\)를 알 수가 없다.
또한, 정밀도가 높은 측정기기로 원소를 측정하더라도 측정 과정에서 발생하는 오차로 인해 원소의 참값을 얻을 수가 없다. 그러나 측정을 반복함으로서 오차를 줄일 수는 있다.
통계적 검정(statistical test): 측정을 통해 얻은 결과가 올바른지 아닌지를 판정하는 과정
대표값 추정
추정(estimation): 참값을 정확하게 알 수는 없지만 어느 정도인지 추측하는 것
점추정(point estimation) : 가장 가능성이 높은 값 하나를 구하는 방법
구간추정(interval estimation): 어느 가능성 하에 통계량이 존재하는 구간을 구하는 방법
추정을 위한 통계량을 얻은 다음, 통계량이 기존의 확률분포를 따른다는 가정하에 추정한다.
추정에 필요한 정보
표본 수 \(n\)
평균: 표본평균 \(\bar{x}\) 또는 모평균 \(\mu\)
분산: 표본분산 \(s^2\) 또는 모분산 \(\sigma^2\)
평균값의 신뢰구간 추정
평균값 점추정 값 = 표본평균 \(\bar{x}\)
평균값 구간추정: 평균값이 들어가는 구간의 신뢰수준(confidence level) 또는 신뢰계수(confidence coefficient)가 주어지면 구할 수 있다. 당연히 신뢰수준이 높을 수록 구간의 폭은 넒어진다.
모집단의 분산을 아는 경우 모평균의 신뢰구간 추정
다음과 같은 통계량을 알고 있다고 가정한다.
표본의 수 \(n\)
표본평균 \(\bar{x}\)
모집단의 분산 \(\sigma^2\)
표본평균 \(\bar{x}\)는 정규분포 \(N\left(\mu,\frac{\sigma^2}{n}\right)\)을 따르므로 표본평균 \(\bar{x}\)을 표준화한 통계량 \(Z\)는 다음과 같다. $$ Z=\frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}} $$ 이 때 통계량 \(Z\)는 표준정규분포 \(N(0,1)\)을 따른다. 예를 들어, 신뢰계수 \(1-\alpha=95\%(=0.95)\)(또는 유의수준(significance level) \(\alpha=0.05\)) 모평균 \(\mu\)가 신뢰구간 안에 있다고 하면, 표준정규분포에 따라 다음과 같이 쓸 수 있다.
$$ \textbf{Pr}(-1.96\leqslant Z \leqslant 1.96) = 0.95 $$
따라서 표준정규분포에서의 신뢰계수 \(1-\alpha\)에 대응하는 표준정규분포의 값을 \(Z_{1-\alpha}\)라고 하면 다음과 같은 식을 얻을 수 있다.
따라서 신뢰수준 \(1-\alpha\)가 주어지면 다음과 같이 모평균의 신뢰구간을 얻을 수 있다. $$ \bar{x}-Z_{1-\frac{\alpha}{2}} \times \frac{\sigma}{\sqrt{n}} \leqslant \mu \leqslant \bar{x} + Z_{1-\frac{\alpha}{2}} \times \frac{\sigma}{\sqrt{n}} $$ \(\alpha\)에 따른 \(Z_{\frac{\alpha}{2}}\)의 값은 표준정규분포표를 통해 알 수 있다.
모집단의 분산을 모르는 경우 모평균의 신뢰구간 추정
다음과 같은 통계량을 알고 있다고 가정한다.
표본의 수 \(n\)
표본평균 \(\bar{x}\)
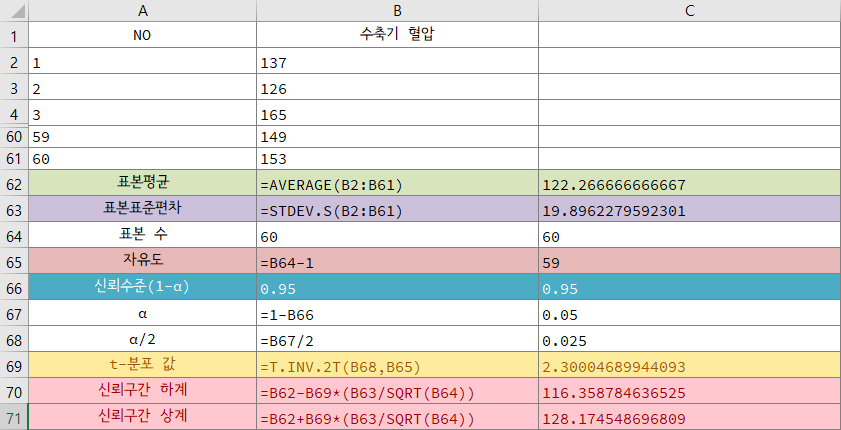
모집단의 분산을 모를 경우에는 표본집단의 분산 \(s^2\)을 사용해 추정을 해야 한다. 모집단의 분산을 아는 경우에는 표본집단이 표준정규분포를 따르겠지만, 표본집단의 분산, 즉 표본분산을 사용해 표준화한 통계량 \(t\)는 다음과 같다. $$ t = \frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}} $$ 이 때, 통계량 \(t\)는 자유도가 \(n-1\)인 \(t\) 분포를 따른다. 따라서 신뢰수준 \(1-\alpha\)가 주어지면 다음과 같이 모평균의 신뢰구간을 얻을 수 있다. $$ \bar{x} - t_{\left(\frac{\alpha}{2}, n-1\right)} \times \frac{s}{\sqrt{n}}\leqslant \mu \leqslant\bar{x} + t_{\left(\frac{\alpha}{2}, n-1\right)} \times \frac{s}{\sqrt{n}} $$
위 식에서 표본의 수 \(n\)이 클 수록 구간의 폭은 줄어들지만, 표본의 크기를 \(100\)배 늘려도 구간의 폭은 \(10\)배 정도 밖에 줄어들지 않기 때문에 효과가 그리 크다고는 말할 수 없다. 또한, 데이터 수집에 많은 비용이 들기 때문에 표본의 크기를 늘리는 데는 한계가 있다. 일반적으로 표본의 수가 작은 경우\(\left(n\lessapprox 30\right)\) 표본표준편차 \(s\)가 작아져도 구간이 폭이 줄어들기 때문에 표본의 산포를 줄일 수 있다면 보다 정확한 추정을 할 수 있다.
엑셀로 모평균의 구간을 추정을 해보자
모분산을 모르는 60개의 표본 데이터가 있을 때, 신뢰계수 \(1-\alpha=95\%=0.95\)(유의수준 \(\alpha=5\%=0.05\))로 모평균의 구간을 추정해보자.
정규분포를 따르는 모집합의 모분산을 \(\sigma^2\)라 할 때, 다음과 같은 통계량을 알고 있다고 가정한다.
표본의 수 \(n\)
표본평균 \(\bar{x}\)
표분분산 \(s^2\)
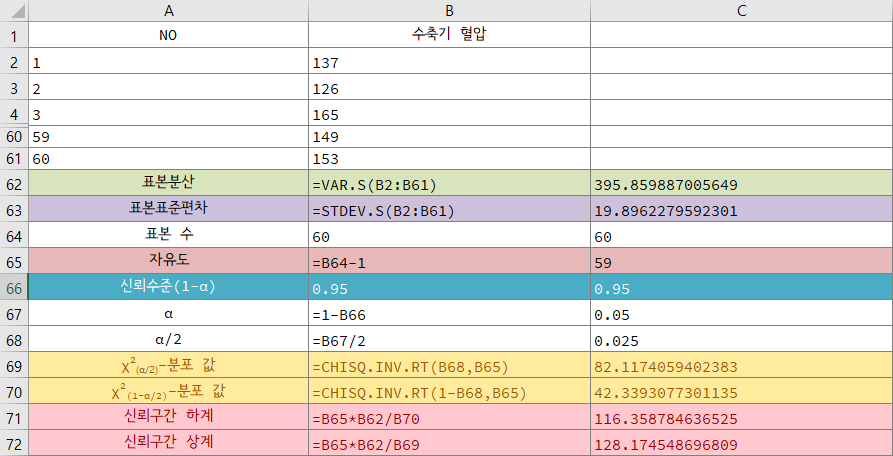
이 때, 통계량 \[\begin{aligned}\chi^2_{(n-1)} &= \frac{(x_1-\bar{x})^2+(x_2-\bar{x})^2+\cdots+(x_n-\bar{x})^2}{\sigma^2}\\ & = \frac{(n-1)s^2}{\sigma^2}\end{aligned}\]
는 자유도 \(n-1\)인 \(\chi^2\)-분포를 따른다고 알려져 있다. 따라서자유도 \(n-1\)인 \(\chi^2\)-분포에서의 신뢰계수 \(1-\alpha\)에 대응하는 \(\chi^2\)-분포의 값을 \(\chi^2_{(n-1)}\)라고 하면 다음과 같은 식을 얻을 수 있다.
따라서 신뢰계수 \(1-\alpha\)가 주어지면 다음과 같이 모분산의 신뢰구간을 추정할 수 있다. $$\begin{aligned} \frac{(n-1)s^2}{\chi^2_{(1-\frac{\alpha}{2},n-1)}} \leqq \sigma^2 \leqq \frac{(n-1)^2}{\chi^2_{(\frac{\alpha}{2},n-1)}}\\\end{aligned} $$
엑셀로 모평균의 구간을 추정을 해보자
모분산을 모르는 60개의 표본 데이터가 있을 때, 신뢰계수 \(95\%\) 또는 유의수준 \(5\%\)로 모평균의 구간을 추정해보자.
표본집단의 원소가 \(n\)개 일 때, 모집단의 평균이나 분산을 모르는 경우, 표본평균이나 표본분산을 이용해 계산한 통계량은 자유도가 \(n-1\)인 분포를 따른다. 이 경우 우리가 어떤 값인지는 모르지만 모평균 \(\mu\)나 모분산 \(\sigma^2\)은 이미 정해져 있는 값이다. 이 때 우리는 \(n\)개의 표본 \(x_1, x_2, \ldots, x_n\)으로 부터 통계량을 계산해야 하는데, \(x_1, x_2, \ldots, x_{n-1}\)의 표본을 구한 다음에 \(n\)번째 표본 \(x_n\)은 어떤 값을 뽑더라도 표본 통계량은 모평균 \(\mu\)나 모분산 \(\sigma^2\)에 가까워야 한다. 즉, \(1\)부터 \(n-1\)개까지의 표본은 자유롭게 선택할 수 있지만 \(n\)번째 표본은 모평균과 모분산에 종속된 값이 되어야 하므로 자유롭게 선택할 수 있는 자유도는 \(n-1\)이 된다.
모분산(population variance): 모집단의 분산 $$ \sigma^2=\frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)^2 $$
표본분산(sample variance): 표본의 분산 $$ s^2=\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2 $$
표준편차(SD, standard deviation)
모표준편차(population standard deviation): 모집단의 표준편차 $$ \sigma=\sqrt{\frac{\sum_{i=1}^{N}(x_i-\mu)^2}{N}} $$
표본표준편차(sample standard deviation): 표본의 표준편차 $$ s=\sqrt{\frac{\sum_{i=1}^{n}(x_i-\bar{x})^2}{n-1}} $$
변동 계수(CV, coefficient of variation): 분포의 산포 정도를 비교하기 위한 표준화(standardization) $$ \nu=\frac{s}{\bar{x}}\times100(%) $$
범위(range) $$ x_{\text{max}}-x_{\text{min}} $$
사분위 범위(IR, interquartile range)
기타 척도
표준오차(standard error): 데이터에서 산출(추정)된 각종 통계량의 오차
왜도 또는 비대칭도(skewness): 데이터 분포의 비뚤어진 정도를 나타내는 통계량으로 분포의 대칭성을 나타낸다 $$ \begin{aligned} g_1 &= \frac{\frac{1}{n}{\sum_{i=1}^n(x_i-\bar{x})^3}}{\Big(\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2\Big)^{3/2}} \&=\frac{n}{(n-1)(n-2)}\sum_{i=1}^n\bigg(\frac{x_i-\bar{x}}{s}\bigg)^3 \end{aligned} $$
첨도(kurtosis): 데이터 분포의 뾰족한 정도를 나타내는 통계량으로 데이터 분포에서 봉우리가 얼마나 뾰족하게 솟아있는지를 가리킨다 $$ g_2 = \frac{\frac{1}{n}{\sum_{i=1}^n(x_i-\bar{x})^4}}{\Big(\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2\Big)^{2}} -3 $$