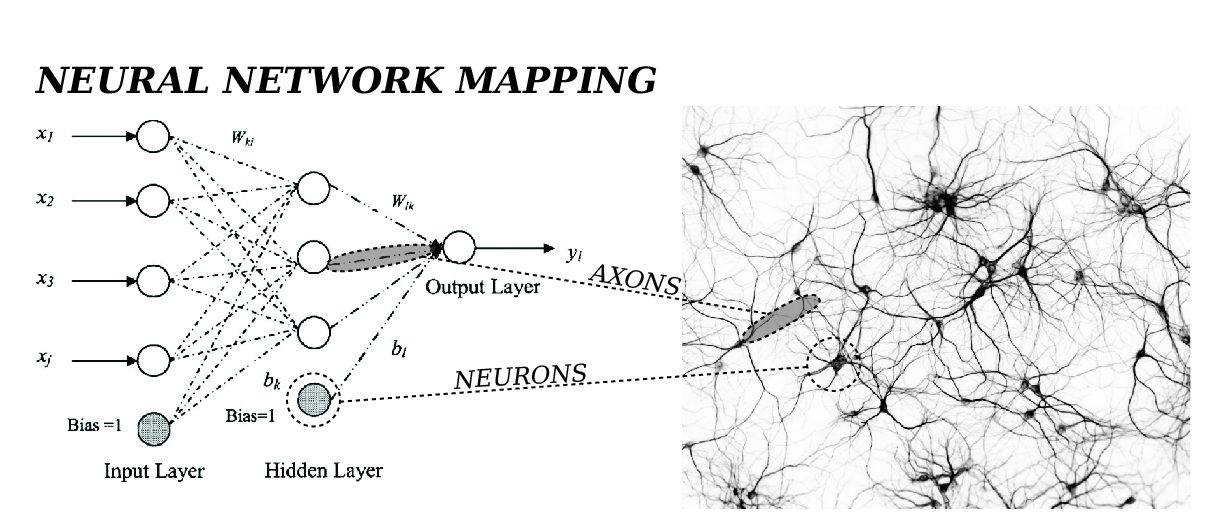
다변수 분류(Multinomial classification) : Softmax classification 연습
Softmax 함수
- \(n\)개의 값을 예측할 때 Softmax 분류 함수를 사용하여 확률분포로 만들어 준다.
- 아래 그림 같이 학습할 데이터 \(\mathbf{X}\)에 학습할 weight \(\mathbf{W}\)를 곱해서 예측값 \(\mathbf{Y}\)를 만드는 것으로 부터 시작한다.

- 즉, 다변수 분류에서 기본 가설식(logit) \(\mathbf{Y}\)는 식 (1)과 같다.
\begin{eqnarray} \mathbf{Y} = \mathbf{X} \mathbf{W} + \mathbf{b} \tag{1} \end{eqnarray}
- 그러나 식 (1)의 결과는 그냥 점수(score)에 불과하다.
- 식 (1)의 결과를 Softmax 함수에 통과시키면 결과가 확률로 나타나 분류대상에 대하여 확률분포를 만들 수 있다. 기본 가설식에 Softmax 함수를 적용한 결과가 우리가 원하는 가설식이다. 즉, 식 (2)가 가설식이다.
\begin{eqnarray} H(x) &=& \textrm{Softmax}(\mathbf{Y})\\ &=& \textrm{Softmax}(\mathbf{X} \mathbf{W} + \mathbf{b}) \tag{2} \end{eqnarray}

Softmax 함수를 사용하는 모델
- 아래 그림과 같이 TensorFlow를 사용하여 수식을 그대로 써주면 된다.
- 기본 가설식 식 (1)은 다음과 같은 코드를 사용한다.
tf.matmul(X,W) + b
- 최종 가설식 식 (2) $H(x)$는 다음과 같은 코드를 사용하여 확률분포를 계산할 수 있다.
hypothesis = tf.nn.softmax(tf.matmul(X,W) + b)

- Cost(Loss) 함수 식 (3)처럼 CROSS-ENTROPY로 표현할 수 있으며, 다음과 같은 코드를 사용한다.
\begin{eqnarray} \textrm{Cost(Loss) ft.} = \frac{1}{N}\sum_i\mathcal{D}(S(\mathbf{W}x_i+\mathbf{b}, L_i) \tag{3}\end{eqnarray}
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)

Softmax 분류 함수를 사용하는 기계 학습 연습
- \(y\) 값은 항상 0과 1을 갖는다는 것이 중요하다.
- 데이터 사용 시 중요한 것은 모양(shape)이다.
x_data = [[1, 2, 1, 1], [2, 1, 3, 2], [3, 1, 3, 4], [4, 1, 5, 5], [1, 7, 5, 5], [1, 2, 5, 6], [1, 6, 6, 6], [1, 7, 7, 7]]
y_data = [[0, 0, 1], [0, 0, 1], [0, 0, 1], [0, 1, 0], [0, 1, 0], [0, 1, 0], [1, 0, 0], [1, 0, 0]]
X = tf.placeholder("float", [None, 4])
Y = tf.placeholder("float", [None, 3])
nb_classes = 3
import tensorflow as tf
x_data = [[1, 2, 1, 1], [2, 1, 3, 2], [3, 1, 3, 4], [4, 1, 5, 5], [1, 7, 5, 5],
[1, 2, 5, 6], [1, 6, 6, 6], [1, 7, 7, 7]]
# y값은 ONE-HOT encoding을 사용해 표현
y_data = [[0, 0, 1], [0, 0, 1], [0, 0, 1], [0, 1, 0], [0, 1, 0], [0, 1, 0],
[1, 0, 0], [1, 0, 0]]
X = tf.placeholder('float', [None, 4])
Y = tf.placeholder('float', [None, 3])
# Y값의 개수가 분류대상(label)의 개수이며, 이를 nb_classes로 설
nb_classes = 3
W = tf.Variable(tf.random_normal([4, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
# 가설식은 softmax 함수를 사용하여 표현
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
# Cost(Loss) 함수는 cross-entropy를 사용하여 표
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# 그래프를 만들자
with tf.Session() as sess:
# 변수 초기화
sess.run(tf.global_variables_initializer())
for step in range(2001):
# 경사하강법을 사용하여 학습을 시킨다
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(f'STEP = {step:04}, cost 함수값 = '
f'{sess.run(cost, feed_dict={X: x_data, Y: y_data})}')
STEP = 0000, cost 함수값 = 1.9889715909957886
STEP = 0200, cost 함수값 = 0.5703549385070801
STEP = 0400, cost 함수값 = 0.45723509788513184
STEP = 0600, cost 함수값 = 0.3804630637168884
STEP = 0800, cost 함수값 = 0.3090059161186218
STEP = 1000, cost 함수값 = 0.24136722087860107
STEP = 1200, cost 함수값 = 0.2168642282485962
STEP = 1400, cost 함수값 = 0.19778816401958466
STEP = 1600, cost 함수값 = 0.18168748915195465
STEP = 1800, cost 함수값 = 0.16792559623718262
STEP = 2000, cost 함수값 = 0.15603584051132202
ONE-HOT Encoding 테스트
# ONE-HOT 인코딩 테스트
a = sess.run(hypothesis, feed_dict={X: [[1, 11, 7, 9]]})
print(f'예측 결과 = {a}, ONE-HOT 인코딩 결과 = {sess.run(tf.arg_max(a, 1))}')
b = sess.run(hypothesis, feed_dict={X: [[1, 3, 4, 3]]})
print(f'예측 결과 = {b}, ONE-HOT 인코딩 결과 = {sess.run(tf.arg_max(b, 1))}')
c = sess.run(hypothesis, feed_dict={X: [[1, 1, 0, 1]]})
print(f'예측 결과 = {c}, ONE-HOT 인코딩 결과 = {sess.run(tf.arg_max(c, 1))}')
# 한번에 여러 개의 값을 넣어 테스트
all = sess.run(hypothesis, feed_dict={X: [[1, 11, 7, 9], [1, 3, 4, 3],
[1, 1, 0, 1]]})
print(f'예측 결과 = {all}, ONE-HOT 인코딩 결과 = {sess.run(tf.arg_max(all, 1))}')
- ONE-HOT 인코딩의 결과가 제대로 나오는 것을 확인할 수 있다.
STEP = 0000, cost 함수값 = 8.209596633911133
STEP = 0200, cost 함수값 = 0.655610203742981
STEP = 0400, cost 함수값 = 0.5474461317062378
STEP = 0600, cost 함수값 = 0.45507490634918213
STEP = 0800, cost 함수값 = 0.3648858666419983
STEP = 1000, cost 함수값 = 0.27533501386642456
STEP = 1200, cost 함수값 = 0.22607706487178802
STEP = 1400, cost 함수값 = 0.20554673671722412
STEP = 1600, cost 함수값 = 0.1882915496826172
STEP = 1800, cost 함수값 = 0.17360061407089233
STEP = 2000, cost 함수값 = 0.16095450520515442
예측 결과 = [[ 2.96840118e-03 9.97021735e-01 9.90122044e-06]], ONE-HOT 인코딩 결과 = [1]
예측 결과 = [[ 0.90273005 0.08834519 0.00892478]], ONE-HOT 인코딩 결과 = [0]
예측 결과 = [[ 2.43163711e-08 3.81419144e-04 9.99618530e-01]], ONE-HOT 인코딩 결과 = [2]
예측 결과 = [[ 2.96840118e-03 9.97021735e-01 9.90122044e-06]
[ 9.02730048e-01 8.83451924e-02 8.92478414e-03]
[ 2.43163711e-08 3.81419144e-04 9.99618530e-01]], ONE-HOT 인코딩 결과 = [1 0 2]
Fancy Softmax Classifier
- Cross-Entropy와 One-hot encdoing, reshape을 이용하여 조금 더 멋진 코드를 만드는 연습을 해보자.
logits을 사용하는 Softmax Cross-Entropy 함수
- logits : 기본 가설식 식 (1)의 결과값이다.
\begin{eqnarray} \textrm{logits} = \mathbf{X} \mathbf{W} + \mathbf{b} \end{eqnarray}
- logits을 사용하여 hypothesis와 Cost(Loss) 함수를 아래 그림의 ①과 같이 작성할 수 있었다.
- Cost(Loss) 함수에서 Y의 값은 one-hot 인코딩 값이다.
- ①번 코드는 계산식에 빼기 연산 및 합과 평균 등의 계산으로 다소 복잡하다.

- ①번 식이 다소 복잡하기 때문에 간단히 하기위해 TensorFlow에서 softmax_cross_entropy_with_logits() 함수를 제공한다.
- softmax_cross_entropy_with_logits() 함수값에 대하여 평균을 구하면 위 그림의 ②번 식과 같이 Cost(Loss) 값을 구할 수 있다.
softmax_cross_entropy_with_logits 함수를 사용하는 모델
- 아래 그림과 같이 동물에 대한 특징이 주어졌을 때 동물을 분류해보자.

- 학습 데이터가 \(n\)개이고, \(Y\) 데이터는 1개이 때문에 \(Y\) 데이터의 차원은 [None, 1]이다.
- Y \(Y\) 의 값은 0~6 사이의 값으로 one-hot encoding 값이 아니기 때문에 변환이 필요하다.
- TensorFlow의 one_hot() 함수를 사용하면 one-hot encoding의 값으로 바꿀 수 있다.
- one-hot() 함수의 입력값은 \(Y\) 값과 \(Y\) 값의 갯수(class)가 된다. 즉, \(0\leqslant Y \leqslant 6\)이기 때문에 \(\texttt{nb_classes} = 7\)이다.
- one-hot() 함수 입력값의 rank가 \(N\)이면 출력값은 \(N+1\)이 된다.
- 예를 들어, 입력값이 [[0], [3]]이라고 하면 rank=2이다. 즉, shape=(2,1)이다.
- 이 때의 출력값은 [[[1000000]], [[0001000]]]이 되어 rank=3이 된다. 즉, shape(2, 1, 7)이 된다.
- 이러한 결과는 우리가 원하는 것이 아니다. 우리는 shape=(2, 7)을 원한다.
- TensorFlow의 reshape() 함수를 사용하면 우리가 원하는 결과를 얻을 수 있다.
- 예를 들어, 입력값이 [[0], [3]]이라고 하면 출력값은 [[1000000], [0001000]]이 되어 우리가 원하는 결과를 얻을 수 있다.
- shape에서 -1은 나머지 모든 것을 의미한다.

softmax_cross_entropy_with_logits 함수를 사용하는 모델의 기계 학습 연습
import tensorflow as tf
import numpy as np
# 동물 학습 데이터를 불러온다.
xy = np.loadtxt('data-04-zoo.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
print(x_data.shape, y_data.shape)
# 0<= Y <= 6
nb_classes = 7
# x1, x2, x3, ..., x16
X = tf.placeholder(tf.float32, [None, 16])
Y = tf.placeholder(tf.int32, [None, 1])
Y_one_hot = tf.one_hot(Y, nb_classes)
print("one_hot", Y_one_hot)
Y_one_hot = tf.reshape(Y_one_hot, [-1, nb_classes])
print("reshape", Y_one_hot)
W = tf.Variable(tf.random_normal([16, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
logits = tf.matmul(X, W) + b
hypothesis = tf.nn.softmax(logits)
cost_i = tf.nn.softmax_cross_entropy_with_logits(logits=logits,
labels=Y_one_hot)
cost = tf.reduce_mean(cost_i)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# 정확도를 파악한다
# 가설식의 값을 확률분포로 변환
prediction = tf.argmax(hypothesis, 1)
# 원래의 값과 같은지 확인
correct_prediction = tf.equal(prediction, tf.argmax(Y_one_hot, 1))
# 평균을 구해 정확도를 산출한다.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(2000):
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
loss, acc = sess.run([cost, accuracy], feed_dict={X: x_data,
Y: y_data})
print(f'STEP = {step:05}, Loss = {loss:.3f}, 정확도 = {acc:.2%}')
# 예측할 수 있는지 살펴보자
pred = sess.run(prediction, feed_dict={X: x_data})
for p, y in zip(pred, y_data.flatten()):
print(f'예측여부 : [{p == int(y)}], 예측값={p:2}, 실제 Y값={int(y):2}')
(101, 16) (101, 1)
one_hot Tensor("one_hot:0", shape=(?, 1, 7), dtype=float32)
reshape Tensor("Reshape:0", shape=(?, 7), dtype=float32)
STEP = 00000, Loss = 7.292, 정확도 = 0.99%
STEP = 00100, Loss = 0.954, 정확도 = 70.30%
STEP = 00200, Loss = 0.566, 정확도 = 84.16%
STEP = 00300, Loss = 0.420, 정확도 = 89.11%
STEP = 00400, Loss = 0.335, 정확도 = 90.10%
STEP = 00500, Loss = 0.279, 정확도 = 94.06%
STEP = 00600, Loss = 0.238, 정확도 = 95.05%
STEP = 00700, Loss = 0.207, 정확도 = 97.03%
STEP = 00800, Loss = 0.182, 정확도 = 97.03%
STEP = 00900, Loss = 0.162, 정확도 = 97.03%
STEP = 01000, Loss = 0.146, 정확도 = 97.03%
STEP = 01100, Loss = 0.132, 정확도 = 97.03%
STEP = 01200, Loss = 0.120, 정확도 = 97.03%
STEP = 01300, Loss = 0.110, 정확도 = 99.01%
STEP = 01400, Loss = 0.101, 정확도 = 99.01%
STEP = 01500, Loss = 0.094, 정확도 = 99.01%
STEP = 01600, Loss = 0.087, 정확도 = 99.01%
STEP = 01700, Loss = 0.082, 정확도 = 99.01%
STEP = 01800, Loss = 0.076, 정확도 = 99.01%
STEP = 01900, Loss = 0.072, 정확도 = 100.00%
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 4, 실제 Y값= 4
예측여부 : [True], 예측값= 4, 실제 Y값= 4
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 4, 실제 Y값= 4
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 2, 실제 Y값= 2
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 2, 실제 Y값= 2
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 2, 실제 Y값= 2
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 4, 실제 Y값= 4
예측여부 : [True], 예측값= 2, 실제 Y값= 2
예측여부 : [True], 예측값= 2, 실제 Y값= 2
예측여부 : [True], 예측값= 3, 실제 Y값= 3
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 1, 실제 Y값= 1
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 5, 실제 Y값= 5
예측여부 : [True], 예측값= 0, 실제 Y값= 0
예측여부 : [True], 예측값= 6, 실제 Y값= 6
예측여부 : [True], 예측값= 1, 실제 Y값= 1